I used to have an action that would allow me to select a URL link in a draft and run a Shortcut to replace it with [title](link).
It was ridiculously slow, and on iOS 14 has started asking me for authorization to access the web Every. Single. Time
So I’ve cobbled together a script using:
a funky regex pattern to detect URLs (found in this action by @ComplexPoint )
It parses through the draft and replaces each occurrence of a well formed URL by a markdown link after fetching the title. It’s relatively fast, automated, and doesn’t need constant reassurance that I do indeed want to reach out to the internet!
It will deal gracefully with pages that DON’T return a title (google?!?)
The only thing I can’t figure out how to do is to leave well formed existing marked down links alone. I guess I’d need to tweak the regex pattern to exclude []() patterns …
One issue with your approach is that you do not look at the context around the URL.
The idea to find all links in a drafts and process them is quite nice, but it falls short of your already md-style links.
I see two ways here - there are surely more than that:
rewrite your parser in a line based way and insert a simple check if you find the braces in the line. If true … add the line without modification (You might do a regex with broad parameters or just look for “](” as a shortcut
Rewrite your regex to allow the as an optional part in your match. Work with something in the style of /(\]\(|)/g - but it will surely be more complex for you. And check for a non empty group to skip the replacement.
Does this help? Do you need more than that two drafted ides?
I’ve put a new version of the ThoughtAsylum Action Group up on the directory just now. It includes an action called TAD-MD-Link Unlinked, in the Markdown section. It is one I’d actually been working on a few weeks back, but I’ve not had much time to work through my list of updates for the library and group lately.
The action is described as follows:
Convert unlinked URLs to Markdown linked URLs. The URL is replaced by a Markdown link using the URL’s page title as the link text. This action will leave HTML source URLs and existing linked URLs unchanged.
I’ve pulled out the function here, and it is hopefully reasonably well commented.
Expand to see the Function Details
// Convert all non-linked URLs as Markdown links using the page name as the title.
String.prototype.TA_mdTitleLinks = function()
{
//Initialise
let objHTTP = HTTP.create();
let strContent = this;
let strURLPattern = new RegExp(".{0,2}(?:(?:https?)://)(?:(?:[a-z\\u00a1-\\uffff0-9]-*)*[a-z\\u00a1-\\uffff0-9]+)(?:\\.(?:[a-z\\u00a1-\\uffff0-9]-*)*[a-z\\u00a1-\\uffff0-9]+)*(?:\\.(?:[a-z\\u00a1-\\uffff]{2,}))(?::\\d{2,5})?(?:[/?#]\\S*)?", "ig")
//Find URL matches
let astrMatches = strContent.match(strURLPattern);
//Remove duplicates so we only have to retrieve page titles once
astrMatches = [...new Set(astrMatches)];
//For each match analyse it and replace it with a full Markdown link if necessary
//Ignore existing Markdown links and HTML URL sources (e.g. HTML links and images also valid in Markdown)
//Continue to cater for URLs in parentheses
astrMatches.forEach(function(strMatch)
{
//Get the first two characters and the URL
let strStart = strMatch.substring(0,2);
let strURL = strMatch.substring(2);
//If the URL happens to be right at the start of the string, we'll be stripping off the start of the URL.
//So we'll add some extra validation here to check the URL and add the two characters back if necessary.
if(!objHTTP.TA_isValidURL(strURL))
{
strStart = "";
strURL = strMatch;
}
//Existing Markdown and HTML links should be ignored
if(strStart == "](") console.log("IGNORE: Matched an existing Markdown link | " + strMatch);
else if (strStart == '="') console.log("IGNORE: Matched an HTML link | " + strMatch);
//Other links are fair game, replace the content
else strContent = strContent.replaceAll(strMatch, strStart + objHTTP.TA_mdTitleLinkFromURL(strURL));
});
//Return the modified string
return strContent;
}
I’d also been looking for negative lookbehind support in regular expressions, but the JavaScript core used by Apple doesn’t support it quite yet, so I adopted a more manual approach and concocted a regular expression that grabs the previous two characters (something I note you also brought up in another thread that I guess is related to this).
I’m checking for ]( for Markdown links, and also for =" for HTML tag sources as HTML is also valid in Markdown.
Hopefully this will work for you, and if it doesn’t quite do what you want, you can use it as a starting point for developing your own solution.
Yes the request was linked to this- I thought it was generic enough to warrant its own thread.
Thanks for taking the time to explicitly show the function details: for all that JavaScript is taking over the automation landscape i find it surprisingly difficult to get good tips!
I’ll test it later today but I think it’s pretty much what I need!
This works really well, and fast! There are a few issues I’m running into that I thought youd like feedback on.
I start with the following draft:
[Salsa Roja — Mark Bittman](https://www.markbittman.com/recipes-1/salsa-roja)
and another link:
[Pois chiches rôtis aux oignons](https://www.ricardocuisine.com/recettes/6402-pois-chiches-rotis-aux-oignons-verts)
let's try a link with brackets
(https://www.markbittman.com/recipes-1/salsa-roja)
or not:
https://www.markbittman.com/recipes-1/salsa-roja
and a last one
https://www.legacyoptic.com/mamiya-rb67.html
First off, https://google.com will break the title fetching part, so i took it out of the initial test draft. I dont know if its just Google, but the action chokes if the title returns as undefined. I’d solved it by putting everything in a try … catch and returning the link as [url](url)
Here’s what i get when running the TAD action:
[Salsa Roja — Mark Bittman[undefined](][undefined](([Salsa Roja — Mark Bittman](https://www.markbittman.com/recipes-1/salsa-roja))))
and another link:
[Pois chiches rôtis aux oignons[undefined](](https://www.ricardocuisine.com/recettes/6402-pois-chiches-rotis-aux-oignons-verts))
let's try a link with brackets
[undefined](([Salsa Roja — Mark Bittman](https://www.markbittman.com/recipes-1/salsa-roja)))
or not:
[Salsa Roja — Mark Bittman](https://www.markbittman.com/recipes-1/salsa-roja)
and a last one
[Mamiya RB67 - Legacy Optic Reviews](https://www.legacyoptic.com/mamiya-rb67.html)
It seems theres a recursion when processing existing markdown links? The url in round brackets may provide a clue?
The other point comes when theres html in the title (the —) . I was playing around with parsing the title as rich text first, before converting to plain, but i cant find my old drafts …
[Salsa Roja — Mark Bittman](https://www.markbittman.com/recipes-1/salsa-roja)
and another link:
[Pois chiches rôtis aux oignons](https://www.ricardocuisine.com/recettes/6402-pois-chiches-rotis-aux-oignons-verts)
let's try a link with brackets
(https://www.markbittman.com/recipes-1/salsa-roja)
let's try a different link with brackets
(https://docs.getdrafts.com/docs/actions/scripting)
or not:
https://www.markbittman.com/recipes-1/salsa-roja
and a last one
https://www.legacyoptic.com/mamiya-rb67.html
And Google?
https://google.com
It produces the following:
[Salsa Roja — Mark Bittman][Salsa Roja — Mark Bittman]([Salsa Roja — Mark Bittman](https://www.markbittman.com/recipes-1/salsa-roja))
and another link:
[Pois chiches rôtis aux oignons](https://www.ricardocuisine.com/recettes/6402-pois-chiches-rotis-aux-oignons-verts)
let's try a link with brackets
[Salsa Roja — Mark Bittman]([Salsa Roja — Mark Bittman](https://www.markbittman.com/recipes-1/salsa-roja))
let's try a different link with brackets
[Scripting - Drafts User Guide](https://docs.getdrafts.com/docs/actions/scripting)
or not:
[Salsa Roja — Mark Bittman](https://www.markbittman.com/recipes-1/salsa-roja)
and a last one
[Mamiya RB67 - Legacy Optic Reviews](https://www.legacyoptic.com/mamiya-rb67.html)
And Google?
[Google](https://google.com)
I didn’t have any issues with the original action and the Google link.
The issue, that still persists in this approach, for one of the links is due to the link appearing twice - both as a valid Markdown link and a parenthesised unlinked URL. The similarly bracketed link for the Drafts web site you’ll note gets updated correctly, and likewise if it is set as a Markdown link it is left unchanged. I believe it is only for this particular combination that the update of the valid Markdown link will occur.
On this final point I had knowingly made an assumption on this point. I figured that people would most likely not have the same URL twice expressed as both a valid link and an unlinked URL in parentheses. The JavaScript is doing replace alls, and if you have a Markdown link, that will get updated a second time by the update that runs against the parenthesised link.
My question now is, is it worth reworking this action to cater for this particular case? To work it differently to account for this case, I think I’d need to do a lot more intensive splitting, processing, and back checking the text before each URL on the draft, and then update each link individually. Drafts is pretty darn fast for the size of most people’s average draft, but the longer the draft, and the more valid repetitions of the same unlinked URL there are in the draft, the slower it will be to run.
But if it doesn’t for you, then I may have a problem with my setup.
As for the rest, I think your initial assumption was correct. Maybe add a caveat that it will behave poorly if the same url is present in both linked and unlinked forms in the draft?
Earlier you referenced https://google.com which is a URL, but google.com is a domain and isn’t a URL. That shouldn’t get picked up to be processed by the link updater at all, let alone cause an error.
Below is some code to take some sample content and try to get the page title for it. Note only the first two are actually well formed URLs.
let objHTTP = HTTP.create();
let strResult1 = objHTTP.TA_getTitleFromURL("https://www.google.com");
let strResult2 = objHTTP.TA_getTitleFromURL("https://google.com");
let strResult3 = objHTTP.TA_getTitleFromURL("www.google.com");
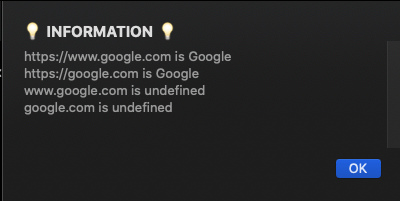
let strResult4 = objHTTP.TA_getTitleFromURL("google.com");
app.TA_msgInfo(`https://www.google.com is ${strResult1}
https://google.com is ${strResult2}
www.google.com is ${strResult3}
google.com is ${strResult4}`);
The result looks like this:
The two URLs return “Google”, and the strings two that lack a protocol just return “undefined”.
There shouldn’t be anything that could be misconfigured for this, so it suggests there is a bug somewhere. What is the text you have in your draft that’s giving you the ‘undefined’?
Sorry for the sloppy referencing. I was speaking of the URLs, And this is extremely weird. Your test sample crashes at the first line, just like the others:
This is getting crazy.
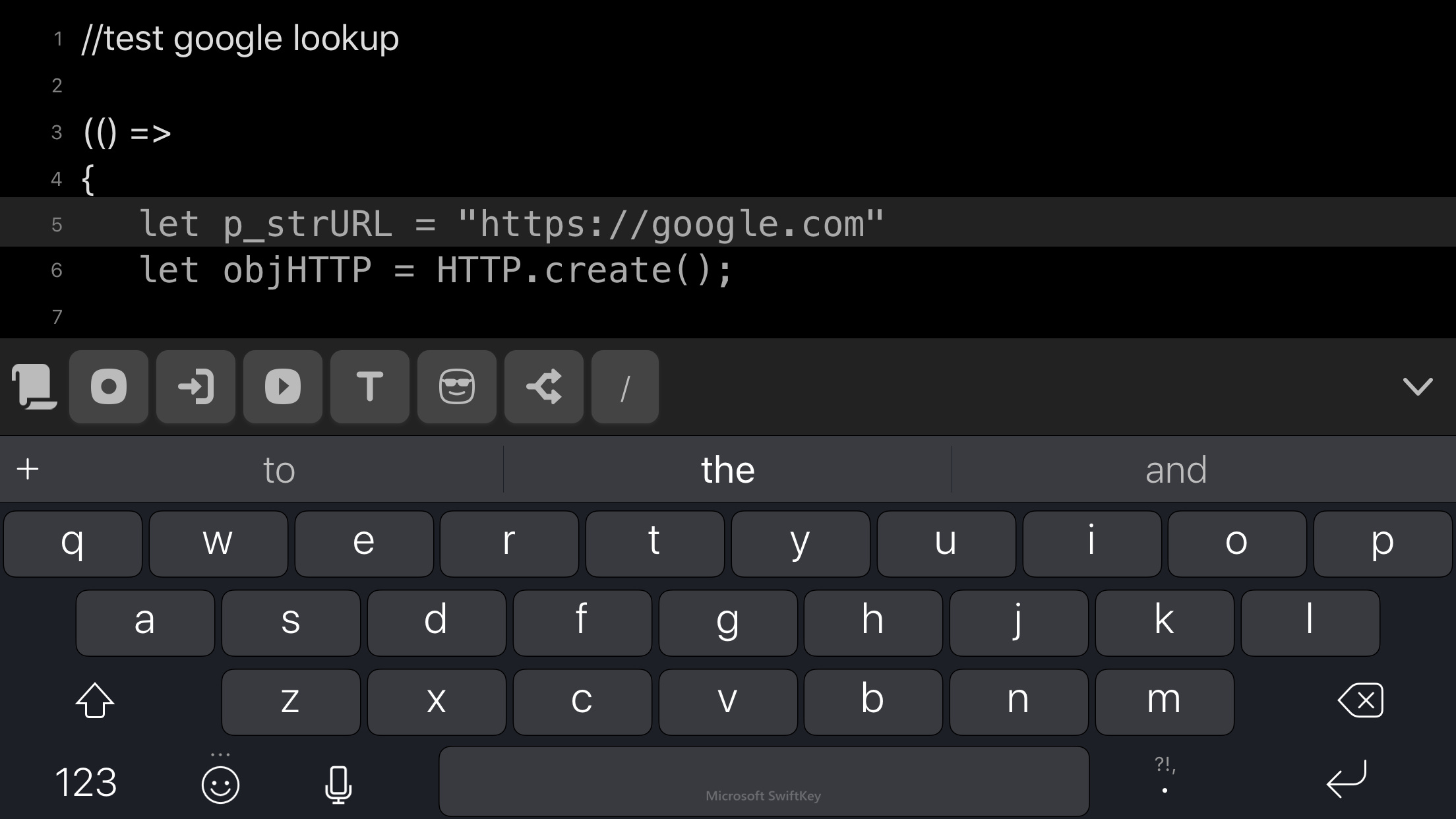
I’ve tested the following script:
//test google lookup
(() => {
let p_strURL="https://www.google.com"
let objHTTP = HTTP.create();
let objResponse = objHTTP.request({"url": p_strURL, "method": "GET"});
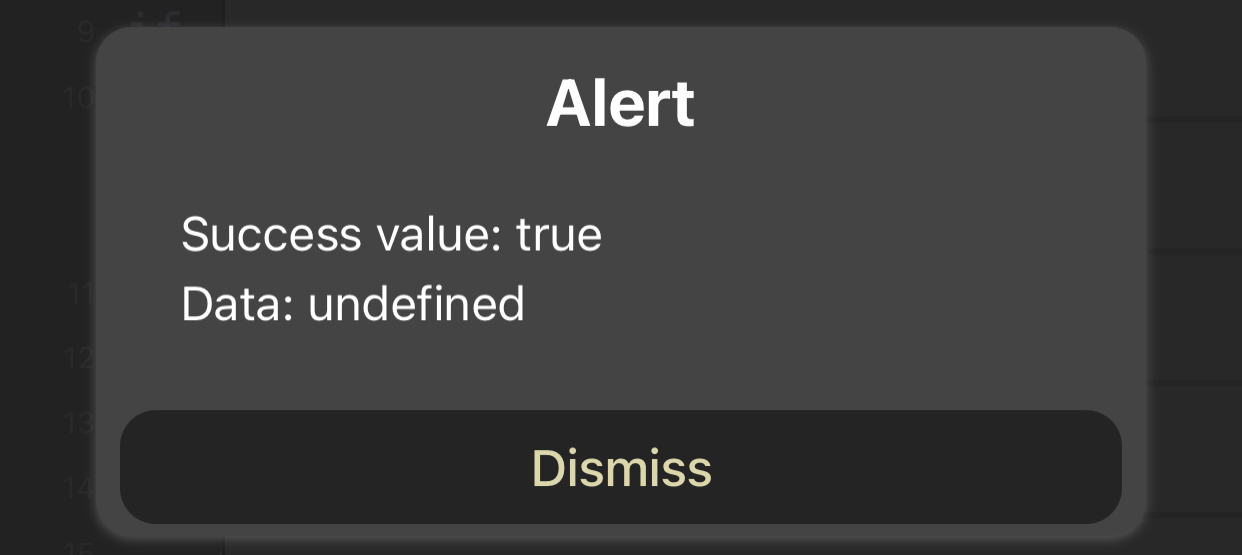
if (objResponse.success){
let resultString='Success value: ' + objResponse.success + '\nData: ' + objResponse.responseText;
alert(resultString);
}
else
{
//Log the URL and result
let resultString="Attempting to fetch title for URL: " + p_strURL + "\n Status code: " + objResponse.statusCode + "\n Error: " + objResponse.error;
alert(resultString);
}
})()
using “TAD-Execute Current Draft”.
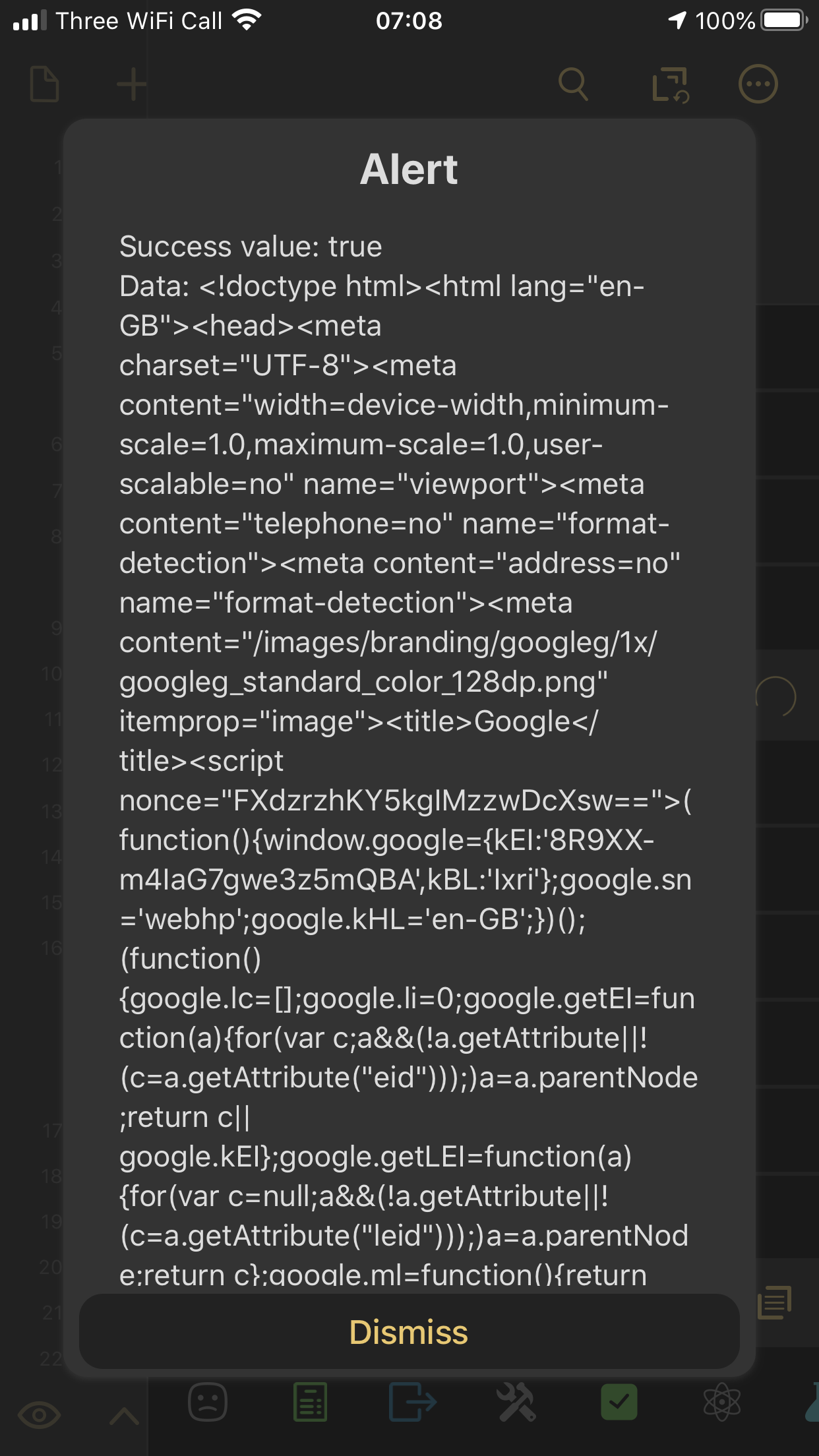
For https://getdrafts.com and other URLs I throw at it, I get a perfectly formed result and I can parse the title.
But for https://google.com I get
We’re both getting a success result, but different results. That suggests it is either something about the local app/OS, or something on the access path that’s filtering.
The test above was run on iOS13.6.1 on Drafts beta version 21.5.33, but the beta change log doesn’t list any fixes for any issues with HTTP.
If it was something on the path, the best thing to do would be to try access over a VPN, but switching wifi/cellular, or using some sort of different connection may suffice depending upon where any filter is, assuming there’s something at all.
It would also be useful to have some others on the forum try it to check their results in case there’s a pattern.
I’m on iOS 14 beta 7 , with the same drafts Beta version (21.5.33)
Unless somebody else can test with ios14 beta, maybe we should set this aside until iOS 14 comes out officially?