I would like to be able to scan text written on the page of a (real) book or my Kindle (not the app) with my iPhone, and end up with plain text in Drafts. Doing so might require multiple steps involving apps like Scanner Pro, Hazel, PDFPenPro, Keyboard Maestro, Shortcuts.
I’m open to any approach. But, I haven’t a clue how to do this and hope that someone else does.
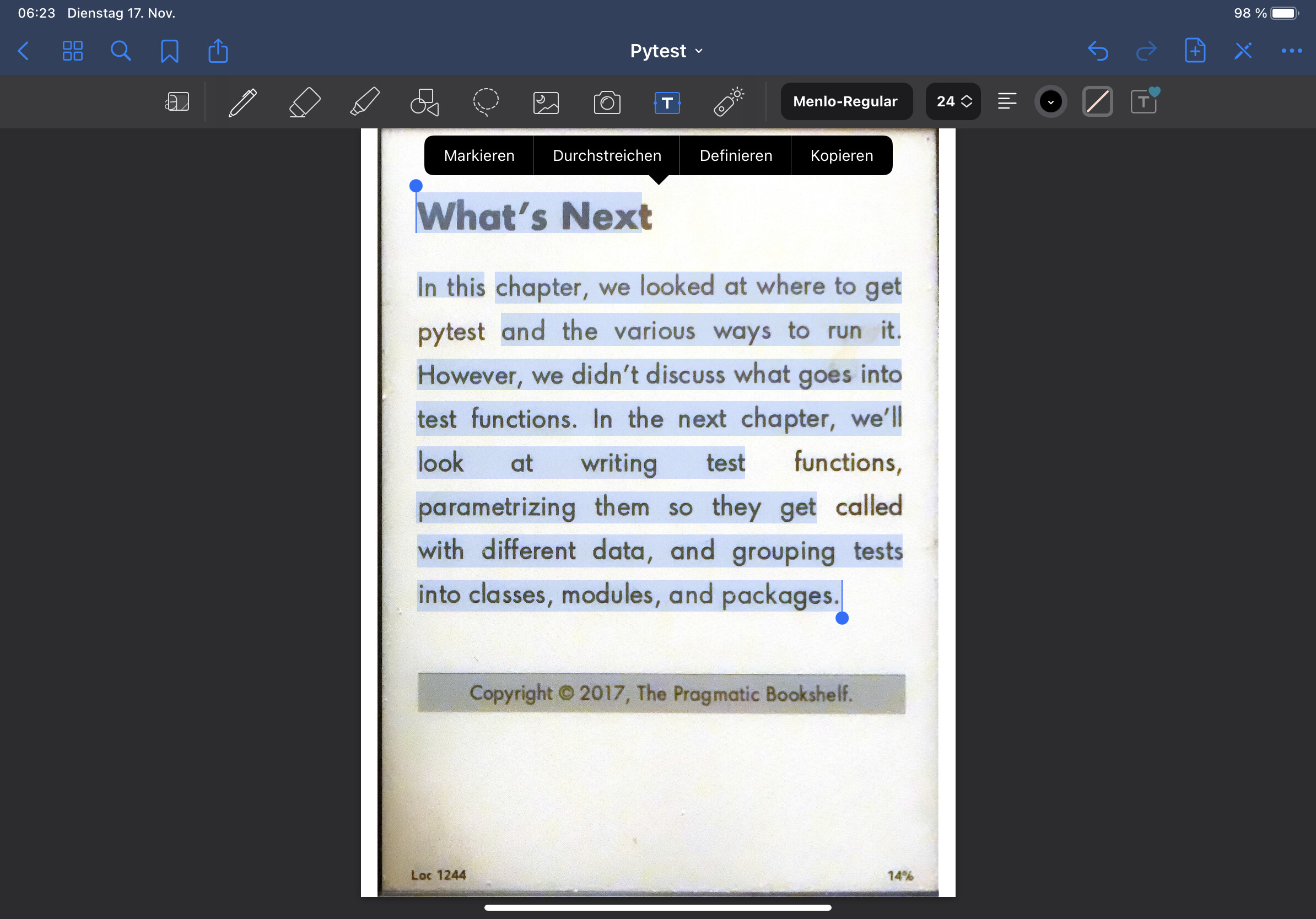
But you can see that it misses out words (even in this very clear font on the kindle).
It is even more strange because the “In this” is not in front of “chapter” but is put before the “However”!
PDFpen should be a tool that has a more advanced OCR.
But OCR might generate this kind problems in any app.
If you use a kindle, you might use the highlight feature and export the notes.
There was even a script to import it into Drafts somewhere here in the forum …
On macOS My knowledge is more limited but I know that ScanSnap Scanners come with a OCR application (I have to look it up).
I did not find that. Is it a feature of the subscription package?
On the Mac, there’s DEVONthink Pro with an integrated OCR and PDFPen. For mobile, there’s Adobe Scan, too. And several others, I think.
However, I’d probably not use a phone to take pictures of a book page but a real scanner. Even with those it’s not easy to have the book lie relatively flat. But with a phone you have to right with the wide angle lense as well.
The suggested Abby App on iOS gets the text this way
What’s Next
In this chapter, we looked at where to get pytest and the various ways to run it. However, we didn’t discuss what goes into test functions. In the next chapter, we’ll look at writing test functions, parametrizing them so they get called with different data, and grouping tests into classes, modules, and packages.
My first attempt at this problem was to use Scanner Pro to scan my Kindle. Scanner Pro worked as designed, creating an OCR’ed PDF. But, that was not useful for Drafts, because I needed plain text, not an OCR’ed PDF.
So, I opened the file on my iMac with PDFPenPro and used it to convert the PDF to plain text. It did it, but with so many formatting errors that it would have been easier for me to type the page than to try to fix the document it created.
Based on the recommendation from @derekvan I tried the app TextGrabber. It works amazingly well. It does the OCR trick, but does not create a PDF. The scanned text is immediately available to send to Drafts (and other places) using a Share menu.
I ran two experiments. The first was with my Kindle. I scanned a page of text. The text was delivered to Drafts with no errors. The entire process takes only a couple of seconds.
The second experiment was with a book I was holding in my lap with one hand while using my other hand to take the picture with my iPhone. It was definitely not a precision operation. But, the text from the page I scanned was sent to Drafts with only a single error. One Drop Cap on the page was misinterpreted.
It’s more expensive (at least it was for me years ago), but will take a physical book opened wide but not pressed flat and de-skew the pages and everything pretty nicely.
 Apparently it was too late yesterday for me.
Apparently it was too late yesterday for me.